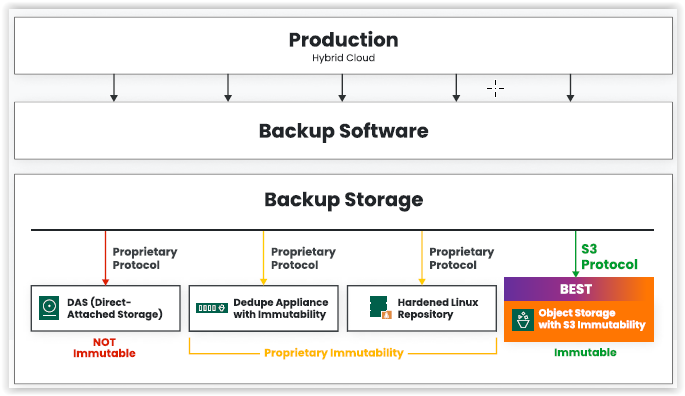
Veeam Data Platform unterstützt zwei Arten an Immutable Backup Repositorys. Das auf XFS aufbauende Linux Hardened Repository und S3 bzw. S3-kompatiblen Objektspeicher.
Object First hat hierzu ein sehr gutes White Paper verfasst. Es kann unter https://objectfirst.com/de angefordert werden. Der Objektspeicher Ootbi (Out-of-the-Box Immutability) ist eine sehr gelungene Lösung, passt aber bei meinen Kunden leider nicht in das Budget für Backupspeicher.
Gehärtete Veeam-Repositorys.
Das gehärtete Repository ist eine Storage-Option für Veeam, die viel Sicherheit, mit etwas Aufwand verbunden, bringt. Mit ein wenig Linux Administrationskenntnissen kann hier ein kostengünstiges Backup Repository aufgebaut werden. Es ist mit Abstand sicherer als direkt angebundener Speicher oder Netzwerkspeicher.
Die Einrichtung und Aktualisierung zur Erhaltung der Sicherheit erfordern aus meiner Sicht nur geringe Linux Kenntnisse und ist auch für Windows Administratoren machbar. Eine gewisse Bereitschaft für eine regelmäßige Aktualisierung des zugrundeliegenden Linux Betriebssystem sollte allerdings vorhanden sein.
Für die Zusammenarbeit mit Veeam wird ein eigener Benutzer eingerichtet. Dieser benötigt bei der Erstinstallation und später bei Updates sudo Rechte, die ihm im normalen Betrieb entzogen werden. Auch das kann sich ein Administrator aneignen und stellt aus meiner Sicht kein unüberwindliches Hindernis dar.
Veeam schreibt die Vollbackupdatei und die Inkrementellen Backupdateien über eine gesicherte API in das Hardened Repository. Hierzu werden zusätzlich zum SSH Port noch die Ports TCP 6160, TCP 6162 und für die Übertragung TCP 2500-3300 benötigt.

Dort wird das Dateisystem Attribut [i] gesetzt und die Backups so vor Veränderung geschützt. Über den Befehl lsattr kann man sich das anzeigen lassen.

Der Schutz hängt an den jeweiligen Backupdateien und verhindert das Löschen aus Veeam heraus.
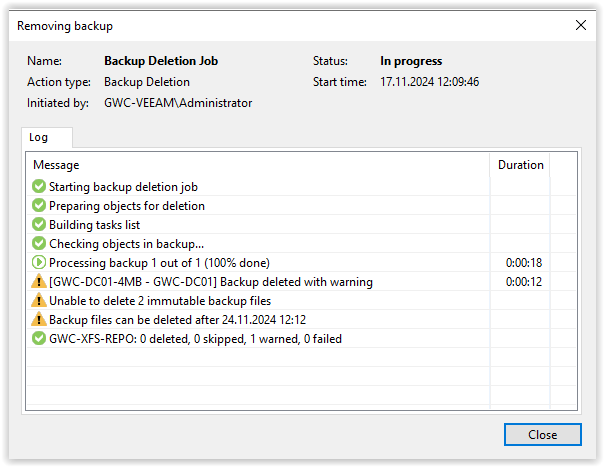
Wenn ein Angreifer aber Zugriff auf das Linux System als root erlangt, dann kann er dieses Attribut löschen und danach auch die Dateien. Wenn das passiert, dann ist zuvor schon an dem Sicherheitskonzept etwas falsch gelaufen. Der SSH Zugang ist in der Umgebung ausschließlich aus dem Backupnetzwerk erreichbar und durch ein komplexes Passwort oder ein Zertifikat gesichert. Aus dem Arbeitsnetzwerk der Benutzer oder gar von extern ist ein Zugriff auf das Linux System durch eine Firewall zu verhindern.
Objektspeicher.
Die Veeam Data Platform kann seit V12 den S3-Objektspeicher auch als primäres Backup-Ziel nutzen. Hierbei wird die Sicherheit des S3-Objektspeichers für die Immutability genutzt. Diese muss bei der Einrichtung der S3 Buckets konfiguriert werden.
Die Kommunikation erfolgt ausschließlich über https. Je nach Objektspeicher kommt hier ein unterschiedlicher Port zur Anwendung. Das vereinfacht die Nutzung aus administrativer Sicht, da auch kein zusätzlicher Transport-Dienst installiert oder später aktualisiert werden muss.
Um die weiteren Unterschiede herauszuarbeiten habe ich hier MINIO als Objektspeicher gewählt. Die Oberfläche von MINIO ist sehr gut und zeigt alle Informationen an.
Wenn man MINIO wie das Linux Hardened Repository als primäres Backupziel auswählt, staunt man nicht schlecht beim Blick auf den Objektspeicher. Aus einer einzigen Vollbackupdatei eines kleinen Windows Domänencontrollers (ca. 11GB) wurden knapp 20.000 Objekte.

Zum einen gibt es keine sichtbare Backupdatei. Die Information hat nur noch Veeam Data Platform. Zum anderen hängt in Form der Metadaten die Immutablity an jedem einzelnen dieser Objekte. Das ist wichtig, wenn andere, folgende Backups auf denselben Objekten aufbauen. Dann verändert Veeam Data Platform die Informationen zu Immuatbility in den Metadaten – und das in der Regel bei sehr vielen Objekten. Wenn diese Metadaten dann zusammen mit den Objekten auf Festplatten liegen, kann das zu einer Herausforderung werden.
Man kann die Anzahl der Objekte reduzieren, indem man die Blockgröße des Veeam Backups von 1MB auf 4 MB verändert. Damit reduziert sich die Anzahl der Objekte auf ein Viertel.

Ich habe Kunden, die haben virtuelle Maschinen mit 30TB Daten. Hier liegt die Objektzahl im 3-stelligen Millionenbereich. Hier nutzen wir CEPH basierten Objektspeicher mit den Objekten auf Festplatten und den Metadaten auf SSDs.
Die Zusammenfassung entnehme ich dem Objectfirst Whitepaper.